193-0801-9605

立即咨询
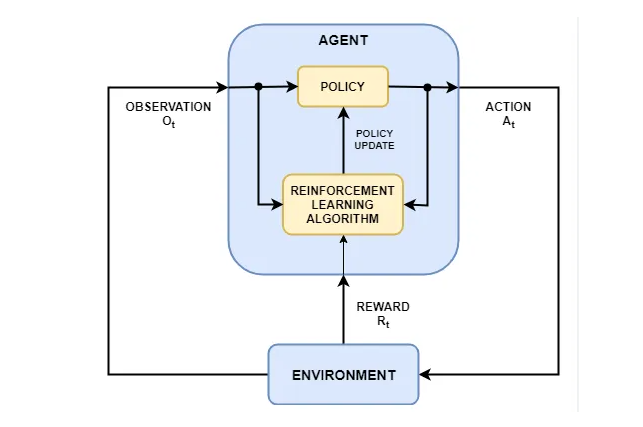
在工程设计与仿真领域,强化学习(RL)的引入为复杂的结构优化问题提供了创新的解决方案。通过动态拓扑优化,RL不仅实现了轻量化与平衡强度,还推动了多目标优化的高效实现。索为将从多种强化学习算法入手,探讨其在CAE仿真中的应用及前景。
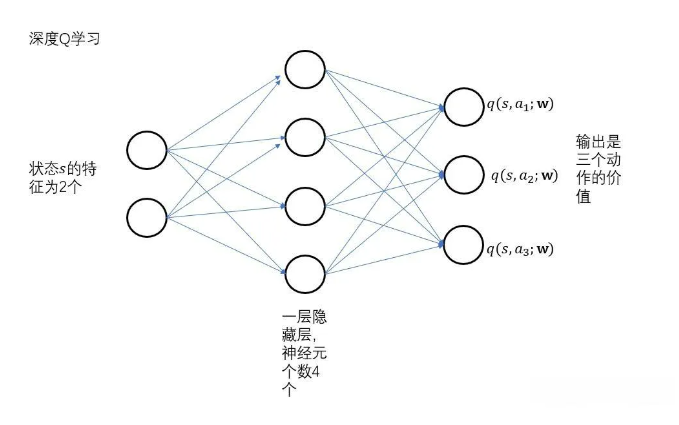
一、深度 Q 学习(Deep Q-Learning, DQN)
DQN 使用深度神经网络近似 Q 值函数,适合离散动作空间的优化问题。在 CAE 仿真中,DQN 可以用于离散的拓扑优化问题,通过生成模型生成初始结构后,DQN 优化结构参数,如删除或增加材料单元,以满足轻量化和强度目标。
二、深度确定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG)
DDPG 是一种适合连续动作空间的强化学习算法,结合策略网络和 Q 网络实现稳定训练。在 CAE 的拓扑优化中,DDPG 适用于连续拓扑参数的优化任务,比如材料厚度或密度分布的调整。生成模型生成初始结构,DDPG 在优化过程中调整拓扑细节,平衡轻量化和强度目标。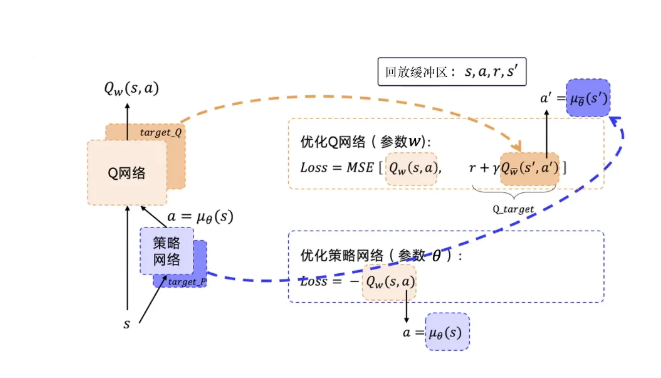
三、近端策略优化(Proximal Policy Optimization, PPO)
PPO 通过剪切策略更新,改善了策略梯度算法的稳定性,适合多目标优化。在 CAE 仿真中,PPO 可以与生成模型结合,优化具有多个目标的拓扑结构设计任务。通过 PPO 进行策略优化,可在轻量化、强度和其他目标之间实现更好的平衡,尤其适用于高维设计参数的多目标优化。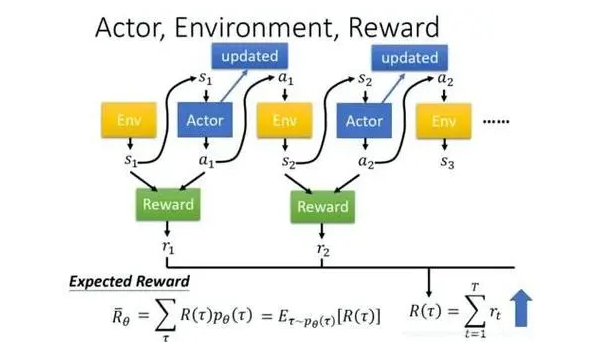
四、策略梯度算法(Policy Gradient, PG)
PG 直接优化策略以最大化奖励函数,适合处理复杂的设计目标。PG 在 CAE 中可以直接优化生成模型的生成策略,帮助模型生成具有轻量化或高强度的结构。它适合复杂的多目标优化任务,通过直接学习生成设计的策略使生成模型更符合设计需求。

五、策略近似和更新(Actor-Critic)
Actor-Critic 通过 Actor 网络和 Critic 网络联合训练,提高学习效率和稳定性。在 CAE 仿真中,Actor-Critic 适合优化多物理场耦合的拓扑结构。Actor 网络生成候选结构,Critic 网络评估结构的轻量化和强度表现,通过多轮迭代优化结构设计。

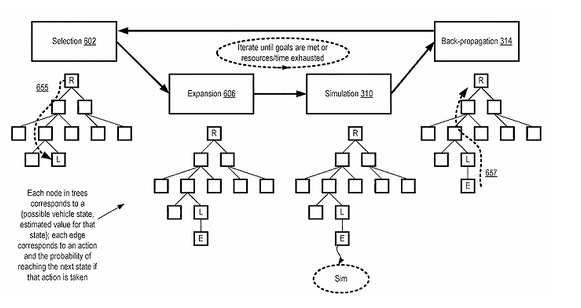
六、蒙特卡洛树搜索强化学习(Monte Carlo Tree Search with RL, MCTS-RL)
MCTS-RL 通过在树结构中探索策略,适合离散和复杂的动作空间。在拓扑优化中,MCTS-RL 可以用于探索和生成可能的结构设计路径。生成模型生成多个设计选择,MCTS-RL 在不同设计路径上进行探索和评估,帮助找到满足轻量化和强度要求的最优设计。
七、软行动评价策略梯度(Soft Actor-Critic, SAC)
SAC 是一种基于熵的算法,在寻求策略最优的同时增加策略探索性,适合多目标优化。在 CAE 仿真中,SAC 适合优化具有多个目标的拓扑结构设计任务,如轻量化、强度和其他约束。SAC 通过增加探索性,找到在生成模型输出基础上符合设计要求的多样化拓扑结构。
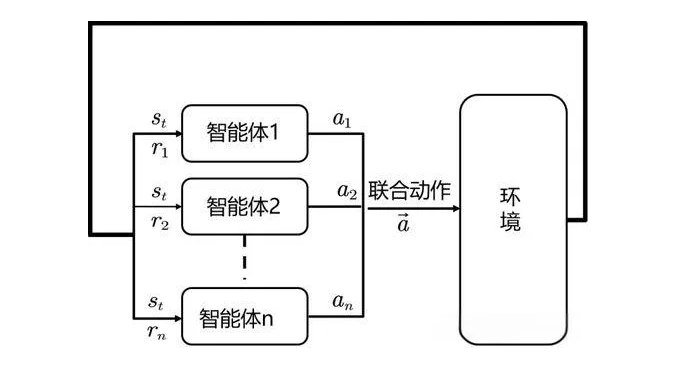
八、多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)
多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)在 CAE 多目标优化中,MARL 可以将不同的智能体分配给不同的目标(如轻量化、强度、材料成本等),各智能体独立优化其目标,最终协同形成满足多目标要求的拓扑结构。
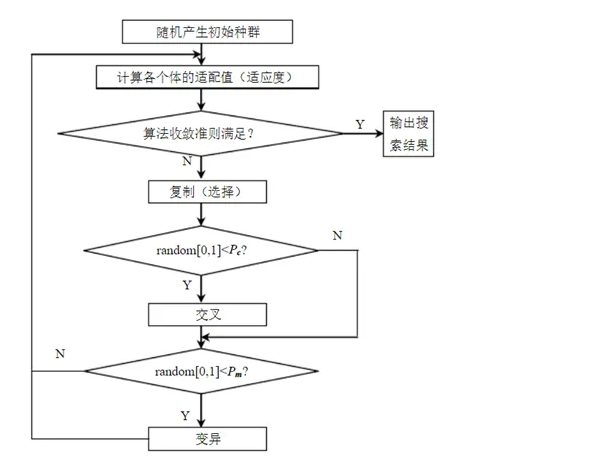
九、遗传算法强化学习(Genetic Algorithm with RL, GA-RL)
GA-RL 结合遗传算法和强化学习,通过遗传算法优化 RL 策略,适合复杂设计空间探索。在 CAE 仿真中,GA-RL 可用于复杂拓扑优化,结合生成模型生成的候选结构,通过遗传算法的交叉和变异操作优化 RL策略,不断优化设计的轻量化和强度表现。
十、自适应强化学习(Adaptive Reinforcement Learning, ARL)
ARL 通过自适应调整奖励函数或策略参数,使 RL 算法更灵活。在 CAE 仿真中,ARL 适合多目标优化问题,通过动态调整奖励函数确保在轻量化和强度之间实现最佳平衡。例如,ARL 可以根据 CAE 仿真反馈信息优化奖励,使设计结构更加符合需求。
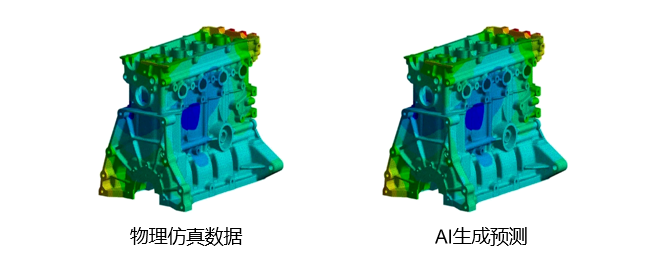
结语
强化学习为CAE仿真领域的拓扑优化与多目标优化注入了强大的动力。从适用于离散空间的深度Q学习到应对复杂的高维设计任务的多智能体强化学习,都有其独特的优势与应用场景。通过结合生成模型与优化算法,强化学习能够高效解决轻量化、强度和其他约束间的冲突,同时加速设计创新。随着强化学习技术的不断进步,未来在工业软件领域的应用必将更加广泛,为复杂结构设计提供更多定制、自动化的解决方案。
想深入了解更多AI技术赋能CAE领域?

